在我们一般的mapreduce程序中,我们只输入一种格式的文件,如果要输入多种问文件格式怎么办呢?
MapReduce多文件输入
MultipleInputs.addInputPath(job, new Path(args[0]),TextInputFormat.class, CounterMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]),TextInputFormat.class, CountertwoMapper.class);
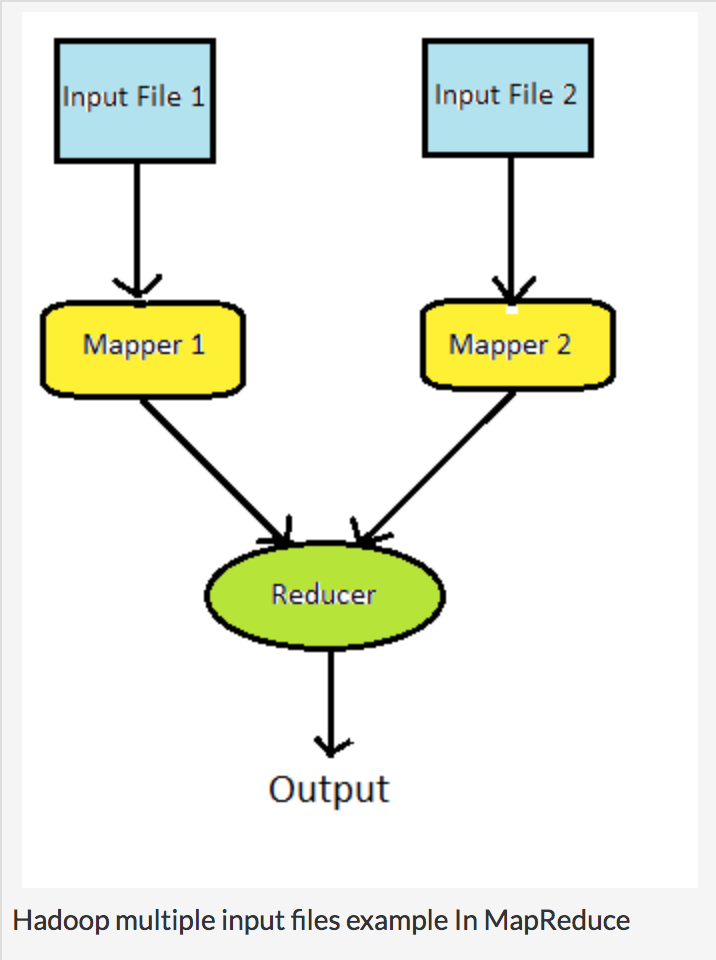
We use MultipleInputs class which supports MapReduce jobs that have multiple input paths with a different InputFormat and Mapper for each path. To understand the concept more clearly let us take a case where user want to take input from two input files with similar structure. Also assume that both the input files have 2 columns, first having “Name” and second having “Age”. We want to simply combine the data and sort it by “Name”. What we need to do? Just two things: Use two mapper classes. Specify the mapper classes in MultipleInputs class object in run/main method.
- Use two mapper classes.
- Specify the mapper classes in MultipleInputs class object in run/main method.
Input Files 1
File1.txt
Aman 19
Tom 20
Tony 15
John 18
Johnny 19
Hugh 17
Input Files 2
File2.txt
James,21
Punk,21
Frank,20
实现Map和Reduce类
Hadoop multiple input files Driver Class
package com.mcis;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.MultipleInputs;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class MultiInputJob extends Configured implements Tool {
public int run(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf);
job.setJarByClass(MultiInputJob.class);
MultipleInputs.addInputPath(job, new Path(args[0]),
TextInputFormat.class, CounterMapper.class);
MultipleInputs.addInputPath(job, new Path(args[1]),
TextInputFormat.class, CountertwoMapper.class);
FileOutputFormat.setOutputPath(job, new Path(args[2]));
job.setReducerClass(CounterReducer.class);
job.setNumReduceTasks(1);
job.setMapOutputKeyClass(LongWritable.class);
job.setMapOutputValueClass(Text.class);
job.setOutputKeyClass(LongWritable.class);
job.setOutputValueClass(IntWritable.class);
return (job.waitForCompletion(true) ? 0 : 1);
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new MultiInputJob(), args);
}
}
Hadoop multiple input files Counter Mapper Class
package com.mcis;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
class CounterMapper extends Mapper<LongWritable, Text, LongWritable,Text>
{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String[] line=value.toString().trim().split("\t");
context.write(new LongWritable(Long.parseLong(line[1])), new Text(line[0]));
}
}
Hadoop multiple input files Counter Two Mapper Class
package com.mcis;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
class CountertwoMapper extends Mapper<LongWritable, Text,LongWritable,Text>
{
public void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException
{
String[] lines=value.toString().trim().split(",");
context.write(new LongWritable(Long.parseLong(lines[1])),new Text(lines[0]));
}
}
Hadoop multiple input files Counter Reducer Class
package com.mcis;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
class CounterReducer extends Reducer<LongWritable,Text,LongWritable,IntWritable>
{
String line=null;
public void reduce(LongWritable key, Iterable<Text> value, Context context ) throws IOException, InterruptedException
{
int count=0;
for (Text text : value) {
count++;
}
context.write(key, new IntWritable(count));
}
}
Output Files
15 1
17 1
18 1
19 2
20 2
21 2